Successor features for transfer in reinforcement learning
Abstract
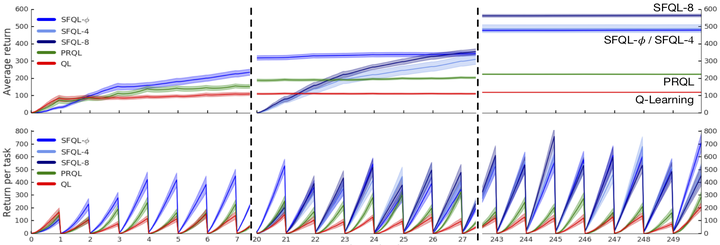
Transfer in reinforcement learning refers to the notion that generalization should occur not only within a task but also across tasks. We propose a transfer framework for the scenario where the reward function changes between tasks but the environment's dynamics remain the same. Our approach rests on two key ideas:” successor features”, a value function representation that decouples the dynamics of the environment from the rewards, and” generalized policy improvement”, a generalization of dynamic programming's policy improvement operation that considers a set of policies rather than a single one. Put together, the two ideas lead to an approach that integrates seamlessly within the reinforcement learning framework and allows the free exchange of information across tasks. The proposed method also provides performance guarantees for the transferred policy even before any learning has taken place. We derive two theorems that set our approach in firm theoretical ground and present experiments that show that it successfully promotes transfer in practice, significantly outperforming alternative methods in a sequence of navigation tasks and in the control of a simulated robotic arm.