Distributional Reinforcement Learning with Quantile Regression
Abstract
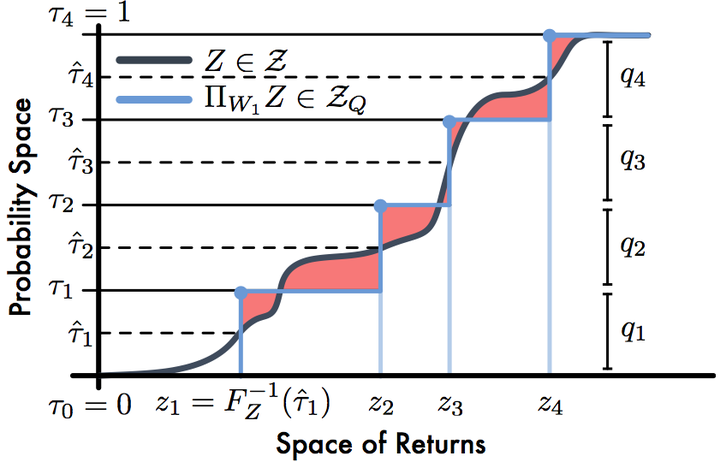
In reinforcement learning an agent interacts with the environment by taking actions and observing the next state and reward. When sampled probabilistically, these state transitions, rewards, and actions can all induce randomness in the observed long-term return. Traditionally, reinforcement learning algorithms average over this randomness to estimate the value function. In this paper, we build on recent work advocating a distributional approach to reinforcement learning in which the distribution over returns is modeled explicitly instead of only estimating the mean. That is, we examine methods of learning the value distribution instead of the value function. We give results that close a number of gaps between the theoretical and algorithmic results given by Bellemare, Dabney, and Munos (2017). First, we extend existing results to the approximate distribution setting. Second, we present a novel distributional reinforcement learning algorithm consistent with our theoretical formulation. Finally, we evaluate this new algorithm on the Atari 2600 games, observing that it significantly outperforms many of the recent improvements on DQN, including the related distributional algorithm C51.

Will Dabney
Research Scientist
Research scientist trying to invent AI, hopefully doing some science along the way.